Kedify Extends KEDA with Predictive, Vertical, and Multi-Cluster Autoscaling for Modern Workloads

by Kedify Team
March 23, 2026
Kedify Extends KEDA with Predictive, Vertical, and Multi-Cluster Autoscaling for Modern Workloads
Kubernetes autoscaling was designed around reactive resource thresholds. That model works for steady workloads, but it struggles under AI inference services, burst-driven APIs, and distributed multi-cluster systems.
The limitation is structural. Resource-based HPA reacts only after saturation is visible. By the time CPU rises, metrics aggregate, and scaling triggers, latency has already degraded. We explored this reactive delay in the following article.
Modern workloads require scaling that anticipates demand, responds to meaningful workload signals, and coordinates consistently across clusters.
Kedify extends KEDA with predictive autoscaling, dynamic vertical resource optimization, multi-cluster coordination, and production-grade enhancements designed for modern infrastructure.
Move beyond reactive autoscaling.
Discover predictive, vertical, and multi-cluster scaling with Kedify.
Get StartedPredictive Autoscaling for Proactive Capacity
Reactive scaling follows a fixed loop. Traffic increases, CPU rises, metrics are evaluated, and replicas are created. The delay window between pressure and response is where instability occurs.
For latency-sensitive AI inference endpoints, even small delays matter. Scaling must account for workload behavior, not just resource exhaustion.
Predictive Autoscaling provisions capacity ahead of expected spikes, reducing cold starts and smoothing traffic surges. Instead of correcting overload after it occurs, the system reduces the likelihood of overload in the first place.
Learn more about predictive autoscaling in our detailed article.
Fast Vertical Scaling for Continuous Resource Optimization
Horizontal scaling alone does not eliminate inefficiency. Many AI and data-intensive services are memory-bound or require dynamic CPU expansion. Static resource requests force teams to overprovision defensively.
Fast Vertical Scaling dynamically adjusts CPU and memory allocation, improving bin packing and reducing fragmentation across the cluster. When combined with predictive horizontal scaling, this approach lowers idle overhead while maintaining responsiveness.
In production environments, this combined strategy has reduced infrastructure costs by up to 40 percent without compromising performance.
Read more about fast vertical scaling in our technical deep dive.
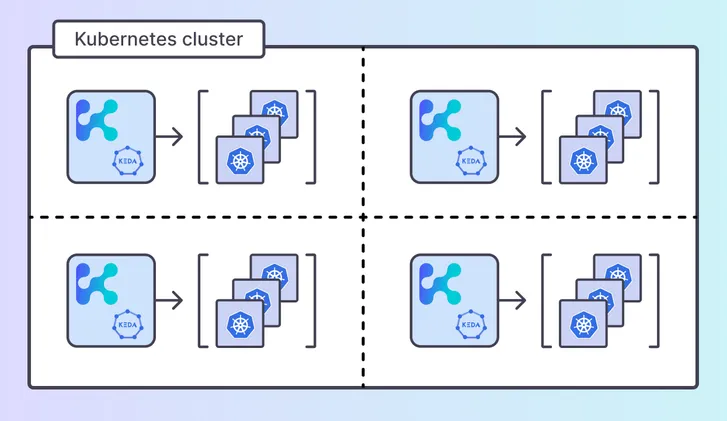
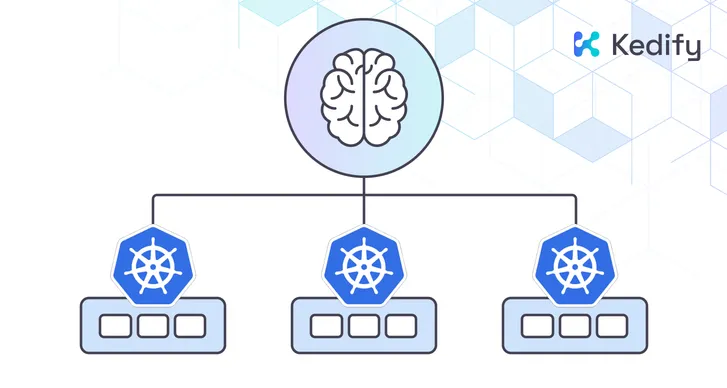
Multi-Cluster Autoscaling for Distributed Environments
Modern production systems rarely operate in a single cluster. High-availability architectures and AI platforms commonly span multiple regions and cloud providers.
Traditional autoscaling mechanisms operate independently per cluster, leading to policy fragmentation and operational inconsistency.
Multi-Cluster Autoscaling introduces centralized scaling intelligence while preserving cluster autonomy. Scaling logic can be applied consistently across distributed environments, reducing complexity and improving reliability.
Explore multi-cluster scaling in more detail.
Extending KEDA for Production-Scale Infrastructure
Kedify is built by the creators and maintainers of KEDA. While KEDA provides powerful event-driven scaling primitives, Kedify adds predictive intelligence, demand-aware scaling, vertical resource optimization, cross-cluster coordination, and multi-tenant KEDA installation designed for production-scale systems.
Kedify is also SOC 2 certified, reinforcing our commitment to security, availability, and operational integrity in enterprise environments.
“Reactive autoscaling introduces unavoidable delays in modern workloads,” says Zbynek Roubalik, co-creator of KEDA and Founder of Kedify. “Infrastructure today requires scaling that anticipates demand, responds to meaningful workload signals, and operates consistently across clusters.”
These capabilities represent part of a broader intelligent autoscaling platform. Kedify continues to evolve KEDA with production-focused enhancements that simplify operations while improving performance and cost efficiency.
Modern Kubernetes workloads demand more than reactive scaling. They require coordinated intelligence across signals, resources, and clusters.
Kedify extends KEDA with an autoscaling layer built for AI-driven and distributed infrastructure.
Learn more at https://www.kedify.io![]() or connect with our team to explore how intelligent autoscaling fits your environment.
or connect with our team to explore how intelligent autoscaling fits your environment.
Built by the core maintainers of KEDA. Battle-tested with real workloads.