Battle of the Pods: Kubernetes Autoscaling Showdown - KEDA vs. Vanilla Kubernetes

October 19, 2023
Navigating Kubernetes’ autoscaling tools can feel like traversing a maze. While tools like HPA and VPA offer certain benefits, they often fall short in addressing complex, real-world scaling needs. Dive into our latest post as we pit KEDA against these traditional tools, exploring how it simplifies autoscaling and stands out in the Kubernetes ecosystem. Discover why KEDA might just be the autoscaling solution you’ve been searching for.
1. Introduction: The Importance of Autoscaling
In today’s cloud-native ecosystem, fluctuating workloads and dynamic traffic patterns are the norm. Accommodating such unpredictable behavior requires systems that can adjust in real-time. Autoscaling is a necessity, ensuring optimal resource allocation, curbing excessive costs, and fostering efficient resource use.
Autoscaling isn’t just about costs. It plays a pivotal role in maintaining application performance and throughput. By avoiding both under-provisioning (leading to poor user experience) and over-provisioning (resulting in unnecessary costs), autoscaling strikes the right balance.
2. The Contenders: Understanding the Basics
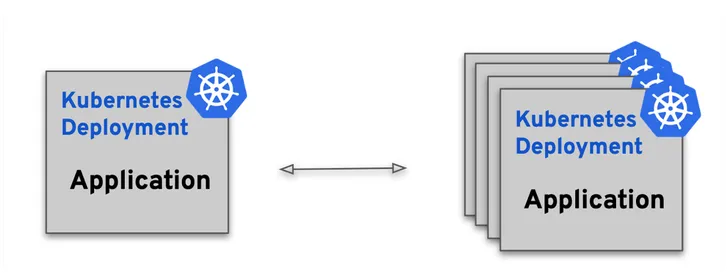
Horizontal Pod Autoscaler (HPA)
HPA![]() , as Kubernetes’ native solution, scales the number of pods based on observed metrics,
primarily CPU and memory. While it’s straightforward and beneficial for uniform workloads, its limitations become evident when you consider its inability to scale to zero and reliance solely on CPU
and memory metrics.
, as Kubernetes’ native solution, scales the number of pods based on observed metrics,
primarily CPU and memory. While it’s straightforward and beneficial for uniform workloads, its limitations become evident when you consider its inability to scale to zero and reliance solely on CPU
and memory metrics.
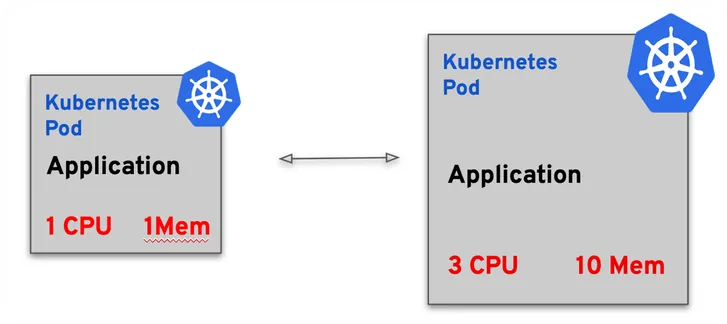
Vertical Pod Autoscaler (VPA)
VPAis more about adjusting resources than expanding them. It gauges the demand and adapts resources dynamically, ensuring the right fit for a workload. But here’s the catch: a beefed-up pod isn’t necessarily better. Sometimes, having more workers process data is more efficient than having one large, powerful worker.
3. The Limitations: When Vanilla Kubernetes Autoscalers Fall Short
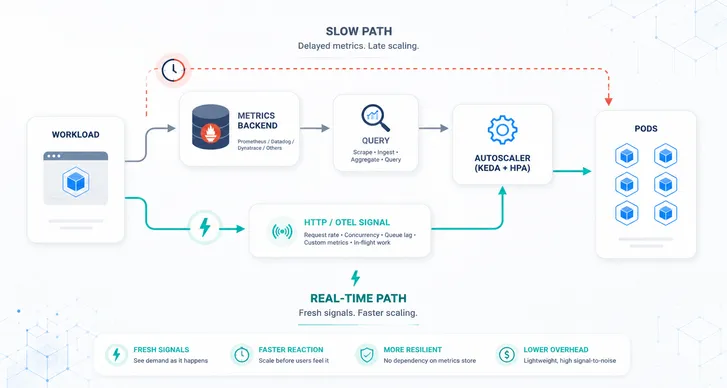
While built-in Kubernetes autoscalers like HPA and VPA provide basic scaling capabilities, they are inherently limited in their scope. Their primary focus on CPU and memory metrics can be a significant limitation for modern applications that might need to react to diverse metrics, some of which might not even emanate from the application itself.
One of the compelling challenges modern applications face is the need to scale in response to events from external systems. For instance:
- Message Queues: Applications might need to scale based on the number of messages in a queue (like RabbitMQ or Kafka). If there’s a surge of unprocessed messages, it might be an indicator to scale up.
- Database Triggers: Changes or updates in a database (like a sudden increase in rows of a particular table) might necessitate an application scale-up to process or analyze the influx of data.
- External Webhooks: Incoming webhooks from third-party services (e.g., GitHub pushes or eCommerce transaction events) could require more resources to handle the additional load.
- IoT Signals: For applications connected to IoT devices, a swarm of signals from these devices might be the metric that necessitates scaling.
Moreover, there are instances where scaling to zero is vital to manage resources efficiently, or scenarios where a combination of different metrics, perhaps CPU utilization coupled with database read/write rates, determines the scaling logic. These nuanced demands highlight the shortcomings of built-in Kubernetes autoscalers.
Custom Metrics Extension for HPA
Kubernetes introduced an interface for custom metrics![]() aiming to offer the Horizontal Pod Autoscaler (HPA) more adaptability beyond just CPU and memory metrics. However, practical implementation has surfaced challenges.
aiming to offer the Horizontal Pod Autoscaler (HPA) more adaptability beyond just CPU and memory metrics. However, practical implementation has surfaced challenges.
While robust, the custom metrics API is not intuitively user-friendly. It demands a detailed grasp of Kubernetes internals, making setup and adjustments cumbersome.
Intermezzo: Prometheus Adapter
Prometheus Adapter![]() attempts to bridge this gap by tapping into the custom metrics API, bringing in Prometheus’
extensive metrics. But it comes with its baggage: a complex, non-intuitive configuration and being tied only to Prometheus metrics. Implementing and upkeeping the configuration demands constant
vigilance. Infrastructure or application changes can trigger the need for reconfigurations.
attempts to bridge this gap by tapping into the custom metrics API, bringing in Prometheus’
extensive metrics. But it comes with its baggage: a complex, non-intuitive configuration and being tied only to Prometheus metrics. Implementing and upkeeping the configuration demands constant
vigilance. Infrastructure or application changes can trigger the need for reconfigurations.
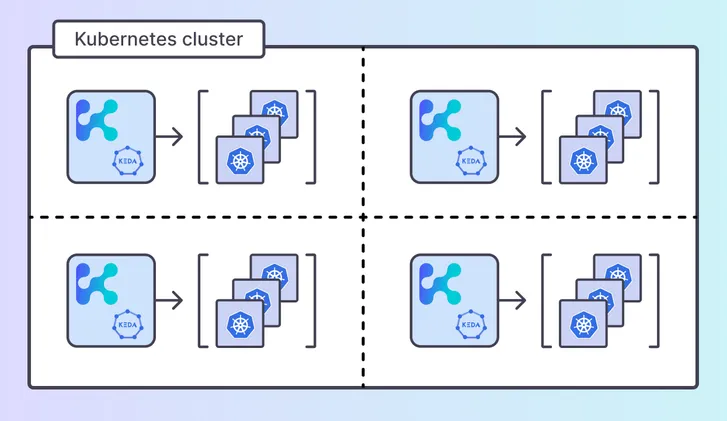
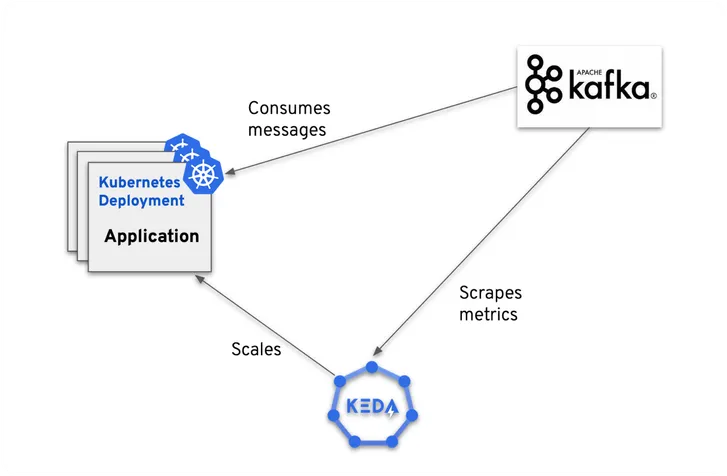
4. Enter KEDA: The Hero of the Showdown
Kubernetes Event-Driven Autoscaling (KEDA)![]() doesn’t just integrate with Kubernetes’ custom metrics API—it makes it accessible. It’s a testament to how
user-friendly interfaces can transform an experience, making autoscaling truly customizable and versatile.
doesn’t just integrate with Kubernetes’ custom metrics API—it makes it accessible. It’s a testament to how
user-friendly interfaces can transform an experience, making autoscaling truly customizable and versatile.
Benefits of KEDA
KEDA offers multiple technical advantages:
- Event-driven autoscaling: KEDA’s ability to respond to specific events, even scaling down to zero, ensures resources are used judiciously.
- Ease of use: Its intuitive configuration makes implementation a breeze, allowing developers to focus on application logic rather than configuration semantics.
- Broad applications: Beyond just scaling pods, KEDA can schedule Kubernetes jobs based on events, ideal for tasks that don’t need constant running but might require significant resources intermittently.
- Versatile integrations: With support for diverse authentication providers, integrating KEDA is both simple and secure.
5. Conclusion: The Future of Autoscaling with KEDA
While Kubernetes has native autoscaling tools like HPA and VPA, and extensions like the Prometheus Adapter, they often come with complexities. KEDA, on the other hand, provides a straightforward platform for diverse autoscaling needs. Its ability to handle event-driven scaling, including scaling to zero, is a significant advantage. Moreover, setting up KEDA is simpler, reducing the typical hurdles users face with Kubernetes’ custom metrics.
KEDA’s active community is a testament to its utility. Regular contributions to the project, vendors like Kedify or Microsoft, and increasing adoption among businesses![]() show its growing importance in the Kubernetes ecosystem.
show its growing importance in the Kubernetes ecosystem.